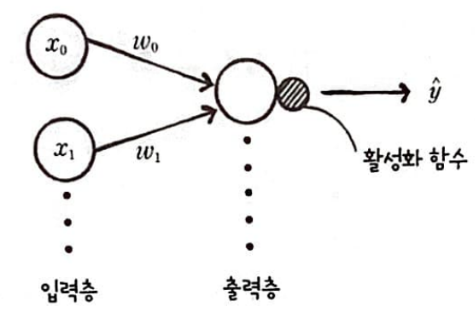
로지스틱 회귀 뉴런의 단일층 신경망
단일층 신경망
입력층과 출력층만 가지는 신경망을 단일층 신경망이라고 한다.

확률적 경사 하강법(stochastic gradient descent)
경사 하강법을 적용할때 샘플 데이터 1개에 대한 그레이디언트를 계산했다.
이를 확률적 경사하강법이라 한다.
배치 경사 하강법(batch gradient descent)
경사 하강법을 전체 훈련에디터를 사용하여 한 번에 그레디언트를 계산하는 방식이다.
미니배치 경사 하강법(mini-batch gradient descent)
전체 샘플 중 몇개의 샘플을 중복되지 않도록 선택하여 그레디언트를 계산하는 방식이다.
확률적 경사 하강법은 샘플 데이터 1개마다 그레디언트를 계산하여 가중치를 업데이트한다.
따라서, 계산 비용이 적은 대신 가중치가 최적 값에 수렴하는 과정은 불안정하다.
하지만, 배치 경사 하강법은 전체 훈련 데이터 세트를 사용 히야 한 번에 그레디언트를 계산하므로 가중치가 최적 값에 수렴하는 과정이 안정적이지만 계산 비용은 많이 든다.
두 개를 합친 것이 미니 배치 경사 하강법이라고 한다.
확률적 경사하강법, 배치 경사 하강법이 최적의 가중치에 수렴하는 과정
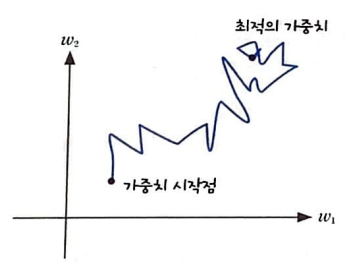
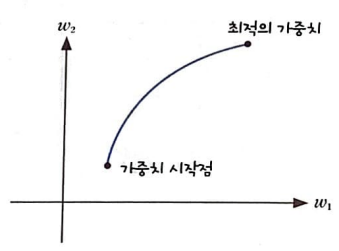
미니배치 경사 하강법은 확률적 경사 하강법 보다는 매끄럽고 배치 경사 하강법보다는 덜 매끄러운 그래프가 그려진다.
# 1. 손실 함수의 결괏 값 저장 기능 추가
| def __init__(self): self.w = None self.b = None self.losses = [] def fit(self, x, y, epochs=100): self.w = np.ones(x.shape[1]) # 가중치를 초기화합니다. self.b = 0 # 절편을 초기화합니다. for i in range(epochs): # epochs만큼 반복합니다 loss = 0 # 인덱스를 섞습니다 indexes = np.random.permutation(np.arange(len(x))) for i in indexes: # 모든 샘플에 대해 반복합니다 z = self.forpass(x[i]) # 정방향 계산 a = self.activation(z) # 활성화 함수 적용 err = -(y[i] - a) # 오차 계산 w_grad, b_grad = self.backprop(x[i], err) # 역방향 계산 self.w -= w_grad # 가중치 업데이트 self.b -= b_grad # 절편 업데이트 # 안전한 로그 계산을 위해 클리핑한 후 손실을 누적합니다 a = np.clip(a, 1e-10, 1 - 1e-10) loss += -(y[i] * np.log(a) + (1 - y[i]) * np.log(1 - a)) # 에포크마다 평균 손실을 저장합니다 self.losses.append(loss / len(y)) |
▶self.losses : __init__ 메서드에 손실 함수의 결과값을 저장할 리스트
샘플마다 손실 함수를 계산하고 그 결괏값을 모두 더한 다음 샘플 개수로 나눈 평균값을 self.losses 변수에 저장
self.activation 메서드로 계산한 a는 np.log의 계산을 위해 한 번 더 조정한다.
a가 0에 가까워지면 np.log값은 음의 무한대가 되고, a가 1에 가까워지면 np.log값은 0이 된다.
손실값이 무한대가 되면 정확한 계산을 할 수 없으므로 a의 값을 np.clip() 함수로 조정해야한다.
np.clip 함수는 주어진 범위 밖의 값을 범위 양 끝의 값으로 잘라낸다.
# 2. 매 에포크마다 훈련 세트의 샘플 순서를 섞어 이용_ (np.random.permutation( ) 함수를 이용)
모든 경사 하강법들은 매 에포크마다 훈련 세트의 샘플 순서를 섞어 가중치의 최적값을 계산해야한다. 훈련 세트의 샘플 순서를 섞으면 가중치 최적값의 탐색 과정이 다양해져 가중치 최적값을 제대로 찾을 수 있기 때문이다.
훈련세트의 샘플 순서를 섞는 전형적인 방법은 넘파이 배열의 인덱스를 섞은 후 인덱스 순서대로 샘플을 뽑는 것이다. 훈련 세트 자체를 섞는 것보다 효율적이고 빠르다.
| def __init__(self): self.w = None self.b = None self.losses = [] def fit(self, x, y, epochs=100): self.w = np.ones(x.shape[1]) # 가중치를 초기화합니다. self.b = 0 # 절편을 초기화합니다. for i in range(epochs): # epochs만큼 반복합니다 loss = 0 # 인덱스를 섞습니다 indexes = np.random.permutation(np.arange(len(x))) for i in indexes: # 모든 샘플에 대해 반복합니다 z = self.forpass(x[i]) # 정방향 계산 a = self.activation(z) # 활성화 함수 적용 err = -(y[i] - a) # 오차 계산 w_grad, b_grad = self.backprop(x[i], err) # 역방향 계산 self.w -= w_grad # 가중치 업데이트 self.b -= b_grad # 절편 업데이트 # 안전한 로그 계산을 위해 클리핑한 후 손실을 누적합니다 a = np.clip(a, 1e-10, 1 - 1e-10) loss += -(y[i] * np.log(a) + (1 - y[i]) * np.log(1 - a)) # 에포크마다 평균 손실을 저장합니다 self.losses.append(loss / len(y)) |
▶ np.random.permutation( ) 함수를 이용하여 index를 섞어 미니 배칭 경사 하강법을 적용할 수 있다.
indexes 배열을 이용하여 정방향계산과 오차를 계산할 때 인덱스를 사용하여 (x[i], y[i]) 샘플을 참조한다.
# 3. predict 메서드 수정 score 메서드 추가
| def predict(self, x): z = [self.forpass(x_i) for x_i in x] # 정방향 계산 return np.array(z) > 0 # 스텝 함수 적용 |
▶ 로지스틱 함수를 적용하지 않고 z값의 크기만 비교하여 반환한다.
왜냐하면 시그모이드 함수의 출력값은 0~1 사이의 확률값이고 양성 클래스를 판단하는 기준은 0.5이상이다. 그런데 z가 0보다 크면 시그모이드 함수 값은 0.5보다 크고, z가 0보다 작으면 시그모이드 함수값은 0.5보다 작다는 의미이다. z가 0보다 큰지 작은지만 따지면 되기 때문에 시그모이드 함수를 사용하지 않아도 된다.
# 4. score 메서드 추가
| def score(self, x, y): return np.mean(self.predict(x) == y) |
▶정확도를 직접 계산 하기 위해 np.mean 함수를 사용한다..
# 5. 최종코드
| class SingleLayer: def __init__(self): self.w = None self.b = None self.losses = [] def forpass(self, x): z = np.sum(x * self.w) + self.b # 직선 방정식을 계산합니다 return z def backprop(self, x, err): w_grad = x * err # 가중치에 대한 그래디언트를 계산합니다 b_grad = 1 * err # 절편에 대한 그래디언트를 계산합니다 return w_grad, b_grad def activation(self, z): z = np.clip(z, -100, None) # 안전한 np.exp() 계산을 위해 a = 1 / (1 + np.exp(-z)) # 시그모이드 계산 return a def fit(self, x, y, epochs=100): self.w = np.ones(x.shape[1]) # 가중치를 초기화합니다. self.b = 0 # 절편을 초기화합니다. for i in range(epochs): # epochs만큼 반복합니다 loss = 0 # 인덱스를 섞습니다 indexes = np.random.permutation(np.arange(len(x))) for i in indexes: # 모든 샘플에 대해 반복합니다 z = self.forpass(x[i]) # 정방향 계산 a = self.activation(z) # 활성화 함수 적용 err = -(y[i] - a) # 오차 계산 w_grad, b_grad = self.backprop(x[i], err) # 역방향 계산 self.w -= w_grad # 가중치 업데이트 self.b -= b_grad # 절편 업데이트 # 안전한 로그 계산을 위해 클리핑한 후 손실을 누적합니다 a = np.clip(a, 1e-10, 1 - 1e-10) loss += -(y[i] * np.log(a) + (1 - y[i]) * np.log(1 - a)) # 에포크마다 평균 손실을 저장합니다 self.losses.append(loss / len(y)) def predict(self, x): z = [self.forpass(x_i) for x_i in x] # 정방향 계산 return np.array(z) > 0 # 스텝 함수 적용 def score(self, x, y): return np.mean(self.predict(x) == y |
# 6. 단일층신경망 훈련하기
| layer = SingleLayer() layer.fit(x_train, y_train) layer.score(x_test, y_test) |
| # 0.9298245614035088 |
▶SingleLayer 객체를 만들고 훈련세트(x_train, y_train) 신경망을 훈련한 후 score 출력한다.
∴
훈련세트를 무작위로 섞어 손실 함수의 값을 줄였기 때문에, 에포크 기본값을 변경하지 않아도 더 좋은 성능을 가져왔다.
# 7. 손실함수 누적값 확인
| layer = SingleLayer() layer.fit(x_train, y_train) layer.score(x_test, y_test) |
| # 0.9298245614035088 |
▶layer 객체의 losses속성에 손실 함수의 결괏값을 저장햇으므로 이 값을 그래프로 그린다.

∴
로지스틱 손실 함수의 값이 에포크가 진행됨에 따라 감소하고 있다.
사이킷런으로 경사 하강법 적용
# 1. 로지스틱 손실함수 지정하기
| from sklearn.linear_model import SGDClassifier sgd = SGDClassifier(loss='log', max_iter=100, tol=1e-3, random_state=42) |
▶SGDClassifier 클래스에 로지스틱 회귀를 적용
loss 매개변수에 손실 함수로 log를 지정한다.
max_iter는 반복 횟수를 나타내는 매개변수로 100번 반복한다.
random_state를 통해 난수 초깃값을 42로 설정한다.
tol은 반복할 때 로지스틱 손실 함수의 값이 변경되는 정도를 컨트롤한다.
만약 tol에 설정한 값보다 적게 변경되면 반복을 중단한다.
# 2. 사이킷런으로 훈련하고 평가
유방암 데이터
| from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split cancer = load_breast_cancer() x_train, x_test, y_train, y_test = train_test_split(cancer.data, cancer.target) sgd = SGDClassifier(loss='log', max_iter=100, tol=1e-3, random_state=42) |
▶사이킷런의 datasets모듈 아래에 있는 load_breast_cancer()함수를 사용하면 불러와진다.
클래스 객체를 만들어 cancer에 저장
훈련데이터 세트 나누기 _ (train_test_split() 이용)
# 데이터 ,타깃 shape 보기
| dir(cancer) |
| # ['DESCR', 'data', 'data_module', 'feature_names', 'filename', 'frame', 'target', 'target_names'] |
| print(cancer.data.shape, cancer.target.shape) |
| # (569, 30) (569,) |
▶cancer의 data와 target 확인, 먼저 입력데이터 data의 크기 확인 하니 569개의 샘플과 30개의 특성이 있다는것을 확인.
특성이 30개나 되기 때문에 산점도로 표현하기 어려움
| sgd.fit(x_train, y_train) sgd.score(x_test, y_test) |
| # 0.8333333333333334 |
▶
# 3.
▶