[ R ] 로지스틱 회귀분석
로지스틱 회귀분석
종속변수와 독립변수 간의 관계를 나타내어 예측 모델을 생성한다는 점에서 선형 회귀분석 방법과 유사
로지스틱 회귀분석의 특징
분석 목적: 종속변수와 독립변수 간의 관계를 통해서 예측 모델 생성
회귀분석과 차이점: 종속변수는 반드시 범주형 변수(예, Yes/No, iris데이터의 species)
정규성: 정규분포 대신에 이항분포를 따른다.
로짓 변환: 종속변수의 출력범위를 0과 1로 조정하는 과정 (예, 혈액형 A → [1, 0, 0, 0]
활용분야: 의료, 통신, 날씨 등 다양한 분야
ex) 날씨 관련 요인 변수로 비(rain) 유무 예측
| install.packages("ROCR") library(car) library(lmtest) library(ROCR) |
#1 데이터 가져오기
| weather = read.csv("C:/weather.csv", stringsAsFactors = F) dim(weather) # 366 15 head(weather) # Date MinTemp MaxTemp Rainfall Sunshine WindGustDir WindGustSpeed # 1 2014-11-01 8.0 24.3 0.0 6.3 NW 30 # 2 2014-11-02 14.0 26.9 3.6 9.7 ENE 39 # 3 2014-11-03 13.7 23.4 3.6 3.3 NW 85 # 4 2014-11-04 13.3 15.5 39.8 9.1 NW 54 # 5 2014-11-05 7.6 16.1 2.8 10.6 SSE 50 # 6 2014-11-06 6.2 16.9 0.0 8.2 SE 44 # WindDir WindSpeed Humidity Pressure Cloud Temp RainToday RainTomorrow # 1 NW 20 29 1015.0 7 23.6 No Yes # 2 W 17 36 1008.4 3 25.7 Yes Yes # 3 NNE 6 69 1007.2 7 20.2 Yes Yes # 4 W 24 56 1007.0 7 14.1 Yes Yes # 5 ESE 28 49 1018.5 7 15.4 Yes No # 6 E 24 57 1021.7 5 14.8 No No str(weather) # 'data.frame': 366 obs. of 15 variables: # $ Date : chr "2014-11-01" "2014-11-02" "2014-11-03" "2014-11-04" ... # $ MinTemp : num 8 14 13.7 13.3 7.6 6.2 6.1 8.3 8.8 8.4 ... # $ MaxTemp : num 24.3 26.9 23.4 15.5 16.1 16.9 18.2 17 19.5 22.8 ... # $ Rainfall : num 0 3.6 3.6 39.8 2.8 0 0.2 0 0 16.2 ... # $ Sunshine : num 6.3 9.7 3.3 9.1 10.6 8.2 8.4 4.6 4.1 7.7 ... # $ WindGustDir : chr "NW" "ENE" "NW" "NW" ... # $ WindGustSpeed: int 30 39 85 54 50 44 43 41 48 31 ... # $ WindDir : chr "NW" "W" "NNE" "W" ... # $ WindSpeed : int 20 17 6 24 28 24 26 24 17 6 ... # $ Humidity : int 29 36 69 56 49 57 47 57 48 32 ... # $ Pressure : num 1015 1008 1007 1007 1018 ... # $ Cloud : int 7 3 7 7 7 5 6 7 7 1 ... # $ Temp : num 23.6 25.7 20.2 14.1 15.4 14.8 17.3 15.5 18.9 21.7 ... # $ RainToday : chr "No" "Yes" "Yes" "Yes" ... # $ RainTomorrow : chr "Yes" "Yes" "Yes" "Yes" ... |
stringsAsFactors = F
#2 변수 선택과 더미 변수 생성
| weather_df <- weather[ , c(-1, -6, -8, -14)] str(weather_df) # 'data.frame': 366 obs. of 11 variables: # $ MinTemp : num 8 14 13.7 13.3 7.6 6.2 6.1 8.3 8.8 8.4 ... # $ MaxTemp : num 24.3 26.9 23.4 15.5 16.1 16.9 18.2 17 19.5 22.8 ... # $ Rainfall : num 0 3.6 3.6 39.8 2.8 0 0.2 0 0 16.2 ... # $ Sunshine : num 6.3 9.7 3.3 9.1 10.6 8.2 8.4 4.6 4.1 7.7 ... # $ WindGustSpeed: int 30 39 85 54 50 44 43 41 48 31 ... # $ WindSpeed : int 20 17 6 24 28 24 26 24 17 6 ... # $ Humidity : int 29 36 69 56 49 57 47 57 48 32 ... # $ Pressure : num 1015 1008 1007 1007 1018 ... # $ Cloud : int 7 3 7 7 7 5 6 7 7 1 ... # $ Temp : num 23.6 25.7 20.2 14.1 15.4 14.8 17.3 15.5 18.9 21.7 ... # $ RainTomorrow : chr "Yes" "Yes" "Yes" "Yes" ... |
예측 이므로 RainToday 데이터는 필요가 없어 제거 후 새로운 데이터 프레임 생성
| weather_df$RainTomorrow[weather_df$RainTomorrow == 'Yes'] <- 1 weather_df$RainTomorrow[weather_df$RainTomorrow == 'No'] <- 0 weather_df$RainTomorrow <- as.numeric(weather_df$RainTomorrow) |
X, Y변수 설정
Y변수를 대상으로 더미 변수를 생성하여 로지스틱 회귀분석 환경 설정
#3 학습데이터와 검정데이터 생성(7:3비율)
| idx <- sample(1:nrow(weather_df ), nrow(weather_df) * 0.7) train <- weather_df[idx, ] test <- weather_df[-idx, ] |
학습데이터 : 70% => 회귀모델 생성할때 쓰일 데이터
검증데이터 : 30%
#4 로지스틱 회귀모델 생성
| weather_model <- glm(RainTomorrow ~ ., data = train, family = 'binomial', na.action=na.omit) weather_model # Call: glm(formula = RainTomorrow ~ ., family = "binomial", data = train, # na.action = na.omit) # # Coefficients: # (Intercept) MinTemp MaxTemp Rainfall Sunshine WindGustSpeed # 161.36505 -0.21320 0.04284 -0.12185 -0.26896 0.07539 # WindSpeed Humidity Pressure Cloud Temp # -0.05259 0.09996 -0.17059 0.15810 0.27543 # # Degrees of Freedom: 250 Total (i.e. Null); 240 Residual # (5 observations deleted due to missingness) # Null Deviance: 229.9 # Residual Deviance: 130 AIC: 152 summary(weather_model) # Call: # glm(formula = RainTomorrow ~ ., family = "binomial", data = train, # na.action = na.omit) # # Deviance Residuals: # Min 1Q Median 3Q Max # -2.1271 -0.4254 -0.2166 -0.0849 2.5727 # # Coefficients: # Estimate Std. Error z value Pr(>|z|) # (Intercept) 161.36505 50.42530 3.200 0.001374 ** # MinTemp -0.21320 0.09222 -2.312 0.020792 * # MaxTemp 0.04284 0.25604 0.167 0.867107 # Rainfall -0.12185 0.06260 -1.947 0.051583 . # Sunshine -0.26896 0.11986 -2.244 0.024832 * # WindGustSpeed 0.07539 0.02904 2.596 0.009444 ** # WindSpeed -0.05259 0.04025 -1.306 0.191414 # Humidity 0.09996 0.03364 2.971 0.002968 ** # Pressure -0.17059 0.04927 -3.463 0.000535 *** # Cloud 0.15810 0.12740 1.241 0.214626 # Temp 0.27543 0.27743 0.993 0.320802 # --- # Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 # # (Dispersion parameter for binomial family taken to be 1) # # Null deviance: 229.90 on 250 degrees of freedom # Residual deviance: 130.05 on 240 degrees of freedom # (5 observations deleted due to missingness) # AIC: 152.05 # # Number of Fisher Scoring iterations: 6 |
glm()함수 : glm(y~x, data, family)
family = ‘binomial’ 속성: y변수가 이항형
#5 로지스틱 회귀모델 예측치 생성
| pred <- predict(weather_model, newdata = test, type = "response") pred result_pred <- ifelse(pred >= 0.5, 1, 0) result_pred table(result_pred) # result_pred # 0 1 # 88 22 |
type=”response”속성: 에측 결과를 0-1사이의 확률값으로 예측치를 얻기 위해서 지정
모델 평가를 위해서 예측치가 확률값으로 제공되기 때문에 이를 이항형으로 변환하는 과정이 필요
Ifelse()함수를 이용하여 예측치의 벡터변수(pred)를 입력으로 이항형의 벡터 변수(result_pred)를 생성
#6 모델평가 – 분류정확도 계산
| table(result_pred, test$RainTomorrow) # result_pred 0 1 # 0 80 8 # 1 8 14 |
#7 ROC(Receiver Operating Characteristic) Curve를 이용한 모델 평가
| pr <- prediction(pred, test$RainTomorrow) prf <- performance(pr, measure = "tpr", x.maeasure = "fpr") plot(prf ) 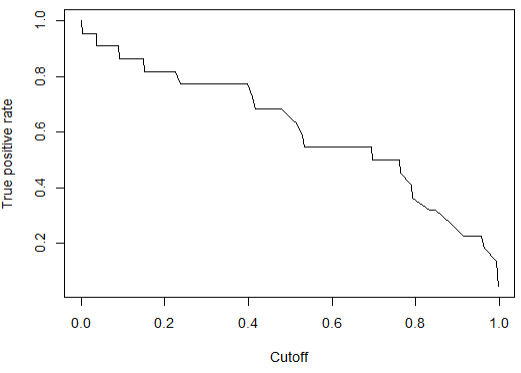 |
ROC curve에서 왼쪽 상단의 계단 모양의 빈 공백만큼이 분류정확도에서 오분류(missing)를 나타낸다.