
59doit
[ R ]EDA 결측치 & 극단치 본문
EDA
- 탐색적 자료분석(Exploratory Data Analysis):
- 수집한 자료를 다양한 각도에서 관찰하고 이해하는 과정
- 그래프나 통계적 방법을 이용하여 자료를 직관적으로 파악하는 과정
(1) EDA 필요성
- 자료의 분포와 통계 파악 : 자료의 특성 이해
- 잠재적인 문제 발견 : 기존의 가설 수정 또는 새로운 방향의 가설 설정
(1) EDA 과정
- 단계별 EDA 수행과정
1. 분석의 목적과 변수의 특징 확인
2. 자료 확인 및 전처리: 결측치, 이상치
3. 자료의 각 변수 관찰: 통계조사, 시각화
4. 변수 간의 관계에 초점을 맞춰 패턴 발견: 상관관계, 시각화 도구로 변수간의 패턴 발견
자료 이해
(1) 데이터 셋 보기
- 데이터의 분포 현황을 통해 데이터의 유형과 결측치(NA), 극단치(outlier)등의 데이터를 발견
- 결측치: 응답자의 회피와 응답할 수 없는 상황(예, 여성의 경우 군필 항목, 남성의 출산여 부 항목)에서 주로 발생
- 극단치: 데이터의 수집과 입력과정에서의 실수로 발생 데이터셋 전체를 볼 수 있는 - print()함수, View()함수
- print()함수: console창으로 데이터 표시
- View()함수: 별도의 데이터 뷰어 창을 통해 전체 데이터를 테이블 양식으로 출력
ex ) 실습용 데이터 가져오기
| dataset <- read.csv("C:/dataset.csv", header = T) dataset |
cf) 전체데이터 보기
print(dataset) View(dataset) => print()함수, View()함수 사용
ex ) 데이터의 앞부분과 뒷부분 보기
| head(dataset) # resident gender job age position price survey # 1 1 1 1 26 2 5.1 1 # 2 2 1 2 54 5 4.2 2 # 3 NA 1 2 41 4 4.7 4 # 4 4 2 NA 45 4 3.5 2 # 5 5 1 3 62 5 5.0 1 # 6 3 1 2 57 NA 5.4 2 tail(dataset) # resident gender job age position price survey # 295 2 1 1 20 1 3.5 5 # 296 1 5 2 26 1 7.1 2 # 297 3 1 3 24 1 6.1 2 # 298 4 1 3 59 5 5.5 2 # 299 3 0 1 45 4 5.1 2 # 300 1 1 3 27 2 4.4 2 |
- head()함수, tail()함수 사용
(2) 데이터 셋 구조 보기
- 데이터 셋의 구조를 확인하는 함수: names(), attributes(), str()함수
- names()함수 데이터 셋의 컬럼명 조회
- attributes(): 열과 행 이름 및 자료구조 정보
- str()함수: 자료구조, 관측치, 칼럼명과 자료형을 동시에 확인
ex ) 데이터 셋 구조 보기
| names(dataset) # [1] "resident" "gender" "job" "age" "position" "price" "survey" attributes(dataset) # $names # [1] "resident" "gender" "job" "age" "position" "price" "survey" # # $class # [1] "data.frame" # # $row.names # [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # [22] 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # [43] 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 # [64] 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 # [85] 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 # [106] 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 # [127] 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 # [148] 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 # [169] 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 # [190] 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 # [211] 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 # [232] 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 # [253] 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 # [274] 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 # [295] 295 296 297 298 299 300 str(dataset) # 'data.frame': 300 obs. of 7 variables: # $ resident: int 1 2 NA 4 5 3 2 5 NA 2 ... # $ gender : int 1 1 1 2 1 1 2 1 1 1 ... # $ job : int 1 2 2 NA 3 2 1 2 1 2 ... # $ age : int 26 54 41 45 62 57 36 NA 56 37 ... # $ position: int 2 5 4 4 5 NA 3 3 5 3 ... # $ price : num 5.1 4.2 4.7 3.5 5 5.4 4.1 675 4.4 4.9 ... # $ survey : int 1 2 4 2 1 2 4 4 3 3 ... |
(2) 데이터셋 조회
- 데이터 셋에 포함된 특정 변수의 내용을 조회하는 방법
- 데이터프레임을 데이터 셋으로 구성한 경우 특정 변수에 접근하기 위해서 ‘$’기호를 사용
- “객체$변수”
ex ) 다양한 방법으로 데이터 셋 조회하기
#1 데이터 셋에서 특정 변수 조회
| dataset$age dataset$resident length(dataset$age) |
#2 특정 변수의 조회 결과를 변수에 저장
| x <- dataset$gender y <- dataset$price x y |
#3 산점도 그래프로 변수 조회
plot(dataset$price)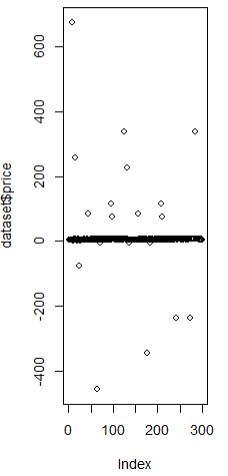 |
#4 컬럼명을 사용하여 특정 변수 조회
| dataset["컬럼명"] dataset["gender"] dataset["price"] |
#5 index를 사용하여 특정 변수 조회
| dataset[2] dataset[6] dataset[3, ] dataset[ , 3] |
#6 2개 이상의 컬럼 조회
| dataset[c("job","price")] dataset[c(2,6)] dataset[c(1,2,3)] dataset[c(2,4:6,3,1)] |
#7 특정 행/열을 조회
| dataset[ , c(2:4)] # 2-4열의 모든 행 조회 dataset[c(2:4), ] dataset[-c(1:100), ] #1-100행 제외한 나머지 행의 모든 열 조회 |
결측치 처리
- 결측치 항목의 최대 자리수 만큼 숫자 9를 채워 부호화 하이픈(-)으로 해당 항목을 채워 놓음
- 결측치를 제거한 후 유효한 자료만을 대상으로 연산: na.rm속성, na.omit()함수 결측치 처리 방법
- 결측치를 제거
- 다른값으로 대체
(1) 결측치 확인
- summary()함수를 이용하여 특정 변수의 결측치 확인
- sum(), mean()함수에 결측치가 포함된 경우 ‘NA’가 출력
ex ) summary()함수를 사용하여 결측치 확인
| summary(dataset$price) # Min. 1st Qu. Median Mean 3rd Qu. Max. NA's # -457.200 4.425 5.400 8.752 6.300 675.000 30 sum(dataset$price) # [1] NA |
- NA 개수 출력
(2) 결측치 제거
- 결측치 제거를 위하여 함수의 속성을 이용하거나 결측치 제거 함수를 사용
ex ) sum()함수의 속성을 이용하여 결측치 제거
| sum(dataset$price, na.rm = T) # [1] 2362.9 |
- na.rm = T 속성 적용
ex ) 결측치 제거 함수를 이용하여 결측치 제거
| price2<-na.omit(dataset$price) sum(price2) # [1] 2362.9 length(price2) # [1] 270 |
- na.omit()_함수는 특정 칼럼의 결측치를 제거
(3) 결측치 대체
- 결측치를 포함한 관측치를 유지하기 위한 벙법:
- 0으로 대체
- 평균으로 대체
ex ) 결측치를 0으로 대체
| x<-dataset$price x[1:30] # [1] 5.1 4.2 4.7 3.5 5.0 5.4 4.1 675.0 4.4 4.9 2.3 4.2 6.7 # [14] 4.3 257.8 5.7 4.6 5.1 2.1 5.1 6.2 5.1 4.1 4.1 -75.0 2.3 # [27] 5.0 NA 5.2 4.7 dataset$price2=ifelse(!is.na(x),x,0) dataset$price2[1:30] # [1] 5.1 4.2 4.7 3.5 5.0 5.4 4.1 675.0 4.4 4.9 2.3 4.2 6.7 # [14] 4.3 257.8 5.7 4.6 5.1 2.1 5.1 6.2 5.1 4.1 4.1 -75.0 2.3 # [27] 5.0 0.0 5.2 4.7 |
ex ) 결측치를 평균으로 대체
| x <- dataset$price x[1:30] # [1] 5.1 4.2 4.7 3.5 5.0 5.4 4.1 675.0 4.4 4.9 2.3 4.2 6.7 # [14] 4.3 257.8 5.7 4.6 5.1 2.1 5.1 6.2 5.1 4.1 4.1 -75.0 2.3 # [27] 5.0 NA 5.2 4.7 dataset$price3 = ifelse(!is.na(x), x, round(mean(x, na.rm = TRUE), 2)) dataset$price3[1:30] # [1] 5.10 4.20 4.70 3.50 5.00 5.40 4.10 675.00 4.40 4.90 2.30 # [12] 4.20 6.70 4.30 257.80 5.70 4.60 5.10 2.10 5.10 6.20 5.10 # [23] 4.10 4.10 -75.00 2.30 5.00 8.75 5.20 4.70 dataset[c('price', 'price2', 'price3')] # price price2 price3 # 1 5.1 5.1 5.10 # 2 4.2 4.2 4.20 # 3 4.7 4.7 4.70 # 4 3.5 3.5 3.50 # 5 5.0 5.0 5.00 # ... ... |
- 결측치, 결측치를 0으로 대체, 결측치를 평균값으로 대체한 컬럼 3개 확인
극단치 처리
극단치(outlier): 정상적인 분포에서 벗어난 값
(1) 범주형 변수 극단치 처리
- 명목척도 같은 범주형 변수
ex ) 범주형 변수의 극단치 처리
| table(dataset$gender) # 0 1 2 5 # 2 173 124 1 pie(table(dataset$gender))  |
- subset()함수: 데이터 셋의 특정 변수를 대상으로 조건식에 해당하는 레코드(행) 추출
- subset(데이터프레임, 조건식)
ex ) subset()함수를 사용하여 데이터 정제
| dataset<-subset(dataset,gender==1|gender==2) dataset # resident gender job age position price survey price2 price3 # 1 1 1 1 26 2 5.1 1 5.1 5.10 # 2 2 1 2 54 5 4.2 2 4.2 4.20 # 3 NA 1 2 41 4 4.7 4 4.7 4.70 # 4 4 2 NA 45 4 3.5 2 3.5 3.50 # 5 5 1 3 62 5 5.0 1 5.0 5.00 # ... ... length(dataset$gender) # [1] 297 pie(table(dataset$gender))  pie(table(dataset$gender), col = c("red", "blue"))  |
(2) 연속형 변수의 극단치 처리
- 연속된 데이터를 갖는 변수들을 대상으로 극단치 확인하고 데이터 정제
ex ) 연속형 변수의 극단치 보기
| dataset <- read.csv("C:/dataset.csv", header = T) dataset$price length(dataset$price) #[1] 300 plot(dataset$price) 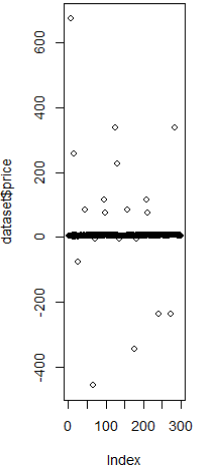 summary(dataset$price) # Min. 1st Qu. Median Mean 3rd Qu. Max. NA's #-457.200 4.425 5.400 8.752 6.300 675.000 30 |
- 산점도 또는 summary()에서 제공되는 요약통계량을 통해 극단치 처리 방법 결정
ex ) price 변수의 데이터 정제와 시각화
| dataset2<-subset(dataset,price>=2&price<=8) length(dataset2$price) # [1] 251 stem(dataset2$price) # The decimal point is at the | # # 2 | 133 # 2 | # 3 | 0000003344 # 3 | 55555888999 # 4 | 000000000000000111111111222333334444 # 4 | 566666777777889999 # 5 | 00000000000000000011111111111222222222333333344444 # 5 | 55555555566667777778888899 # 6 | 00000000000000111111112222222222222333333333333333344444444444 # 6 | 55557777777788889999 # 7 | 000111122 # 7 | 777799 |
- stem()함수를 사용하여 정보를 줄기와 잎 형태로 도표화
ex ) age 변수의 데이터 정제와 시각화
# age 변수에서 NA 발견
| summary(dataset2$age) # Min. 1st Qu. Median Mean 3rd Qu. Max. NA's # 20.0 28.5 43.0 42.6 54.5 69.0 16 length(dataset2$age) # [1] 251 |
# age 변수 정제(20 ~ 69)
| dataset2 <- subset(dataset2, age >= 20 & age <= 69) length(dataset2) # [1] 7 |
# box 플로팅으로 평균연령 분석
boxplot(dataset2$age) |
- boxplot()함수: 정제된 결과를 상자 그래프로 시각
(3) 극단치를 찾기 어려운 경우
- 범주형 변수는 극단치 발견이 상대적 쉽다.
- 연속형 변수는 극단치 찾기가 어려울 수 있다.
- boxplot과 통계 이용하여 극단치 찾기
ex ) boxplot과 통계를 이용한 극단치 처리하기
변수 상/하위 0.3%를 극단치로 설정
#1 boxplot로 price의 극단치 시각화
boxplot(dataset$price) |
#2 극단치 통계 확인
| boxplot(dataset$price)$stats # [,1] # [1,] 2.1 # [2,] 4.4 # [3,] 5.4 # [4,] 6.3 # [5,] 7.9 |
#3 극단치를 제거한 서브 셋 만들기
| dataset_sub <- subset(dataset, price >= 2 & price <= 7.9) summary(dataset_sub$price) # Min. 1st Qu. Median Mean 3rd Qu. Max. # 2.100 4.600 5.400 5.361 6.200 7.900 |
'Programming > R' 카테고리의 다른 글
| [ R ] EDA - 파생변수 (0) | 2022.11.21 |
|---|---|
| [ R ]EDA 코딩변경 (0) | 2022.11.21 |
| [ R ]reshape2 패키지 활용 (0) | 2022.11.20 |
| [ R ] dplyr 패키지 활용 #3 (0) | 2022.11.19 |
| [ R ] dplyr 패키지 활용 #2 (0) | 2022.11.19 |
