
59doit
순환신경망 (3) 본문
임베딩층으로 순환신경망 모델 성능 높이기
순환 신경망의 가장 큰 단점 중 하나는 텍스트 데이터를 원-핫 인코딩으로 전처리한다는 것이다.
원-핫 인코딩을 사용하면 입력 데이터 크기와 사용할 수 있는 영단어의 수가 제한된다는 문제가 있다.
또 원-핫 인코딩은 '단어 사이에는 관련이 전혀 없다'는 가정이 전제되어야 한다.
이런 문제를 해결하기 위해 고안된 것이 단어 임베딩(word embedding)이다.
단어 임베딩이란 단어를 고정된 길이의 실수 벡터로 임베딩 하는 것이다.
원-핫 인코딩을 변경한다면 성능을 올릴 수 있다.
# 1.Embedding클래스 임포트하기
| from tensorflow.keras.layers import Embedding |
▶텐서플로는 Embedding클래스로 단어 임베딩을 제공한다
# 2. 훈련 데이터 준비하기
| (x_train_all, y_train_all), (x_test, y_test) = imdb.load_data(skip_top=20, num_words=1000) for i in range(len(x_train_all)): x_train_all[i] = [w for w in x_train_all[i] if w > 2] x_train = x_train_all[random_index[:20000]] y_train = y_train_all[random_index[:20000]] x_val = x_train_all[random_index[20000:]] y_val = y_train_all[random_index[20000:]] |
▶단어 임베딩은 단어를 표현하는 벡터의 크기를 임의로 지정할 수 있으므로 사용하는 단어의 개수에 영향을 받지 않는다.
# 3. 샘플길이 맞추기
| maxlen=100 x_train_seq = sequence.pad_sequences(x_train, maxlen=maxlen) x_val_seq = sequence.pad_sequences(x_val, maxlen=maxlen) |
▶
# 4. 모델 만들기
| model_ebd = Sequential() model_ebd.add(Embedding(1000, 32)) model_ebd.add(SimpleRNN(8)) model_ebd.add(Dense(1, activation='sigmoid')) model_ebd.summary() |
| Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) (None, None, 32) 32000 simple_rnn_3 (SimpleRNN) (None, 8) 328 dense_2 (Dense) (None, 1) 9 ================================================================= Total params: 32,337 Trainable params: 32,337 Non-trainable params: 0 _________________________________________________________________ |
▶원 핫 인코딩된 입력 벡터의 길이는 100이었지만, 단어 임베딩에서는 길이를 32로 줄여보기
Embedding클래스에 입력한 매개변수는 단어 개수와 출력길이이다.
SimpleRNN 셀 개수를 8로 줄여보기 -> 임베딩층의 성능이 뛰어나기 때문에 셀 개수가 적어도 좋은 성능을 얻을 수 있다.
# 5. 모델 컴파일 & 훈련
| model_ebd.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) history = model_ebd.fit(x_train_seq, y_train, epochs=10, batch_size=32, validation_data=(x_val_seq, y_val)) |
▶val_accracy 값을 보면 이전보다 성능이 크게 향상된것을 확인 할 수 있음
# 6. 손실 그래프와 정확도 그래프
| plt.plot(history.history['loss']) plt.plot(history.history['val_loss']) plt.show() plt.plot(history.history['accuracy']) plt.plot(history.history['val_accuracy']) plt.show() |
▶
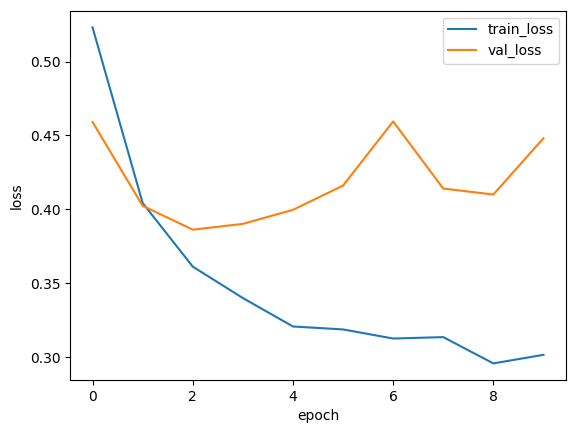

# 7. 정확도
| loss, accuracy = model_ebd.evaluate(x_val_seq, y_val, verbose=0) print(accuracy) |
| # 0.8113999962806702 |
▶
원핫인코딩을 사용하지 않아 메모리 사용량이 절감되었으며 적은 셀 개수에서도 더 높은 성능을 내었다.
단어임베딩은 효율적이고 성능이 뛰어나기 때문에 순환신경망에서 텍스트 처리를 할 때 임베딩층을 기본으로 사용한다.
SimpleRNN클래스와 임베딩층을 사용하니 텍스트 데이터를 조금 더 효율적으로 처리할 수 있었다.



