
59doit
[ R ] 상관분석 본문
상관분석
변수들 간의 관련성을 분석하기 위해 사용하는 분석 방법 하나의 변수가 다른 변수와 관련성이 있는지,
있다면 어느 정도의 관련성이 있는지를 개관할 수 있는 분석기법
상관관계 분석 수행 시, 회귀분석에서 변수 간의 인과관계를 분석하기 전에 변수 간의 관련성을 분석하는 선행자료 (가설검정 전 수행) 로 이용 변수 간의 관련성을 위해 상관계수인 피어슨(Pearson) 계수를 이용하여 관련성 유무와 정도를 파악한다.
상관계수 r은 -1~+1 까지의 값을 가진다.
가장 높은 완전 상관관계의 상관계수 : 1
두 변수 간에 전혀 상관관계가 없으면 상관계수 : 0
(1) 상관계수 r과 상관관계 정도
(2) 상관관계 분석 수행
제품의 친밀도, 적절성, 만족도 변수를 대상으로 변수 간의 상관계수를 통해서 상관관계 분석을 수행
ex) 기술통계량 구하기
#1 데이터 가져오기
| product <- read.csv("C:/Rwork/dataset2/product.csv", header = TRUE) head(product) # 제품_친밀도 제품_적절성 제품_만족도 # 1 3 4 3 # 2 3 3 2 # 3 4 4 4 # 4 2 2 2 # 5 2 2 2 # 6 3 3 3 |
#2 기술통계량
| summary(product) # 제품_친밀도 제품_적절성 제품_만족도 # Min. :1.000 Min. :1.000 Min. :1.000 # 1st Qu.:2.000 1st Qu.:3.000 1st Qu.:3.000 # Median :3.000 Median :3.000 Median :3.000 # Mean :2.928 Mean :3.133 Mean :3.095 # 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.000 # Max. :5.000 Max. :5.000 Max. :5.00 sd(product$제품_친밀도); sd(product$제품_적절성); sd(product$제품_만족도) # [1] 0.9703446 # [1] 0.8596574 # [1] 0.8287436 |
ex) 상관계수 보기
변수간의 상관계수는 stats패키지에서 제공하는 cor()함수 사용
cor(x, y=NULL, use=”everything”, method=c(“pearson”, “kendall”, “spearman”)
method를 생략하면 pearson이 사용된다(default)
#1 변수 간의 상관계수 보기
| cor(product$제품_친밀도, product$제품_적절성) # 0.4992086 cor(product$제품_친밀도, product$제품_만족도) # 0.467145 |
#2 제품_적절성과 제품_만족도의 상관계수 보기
| cor(product$제품_적절성, product$제품_만족도) # 0.7668527 |
#3 (제품_적절성+제품_친밀도)와 제품_만족도의 상관계수 보기
| cor(product$제품_적절성+product$제품_친밀도, product$제품_만족도) # 0.7017394 |
ex) 전체 변수 간의 상관계수 보기
대각선은 자기 상관계수를 의미
| cor(product, method='pearson') # 제품_친밀도 제품_적절성 제품_만족도 # 제품_친밀도 1.0000000 0.4992086 0.4671450 # 제품_적절성 0.4992086 1.0000000 0.7668527 # 제품_만족도 0.4671450 0.7668527 1.0000000 |
ex) 방향성 있는 색상으로 표현
corrgram 패키지 설치 (R 4.0)
| install.packages("corrgram") library(corrgram) corrgram(product) |

| corrgram(product, upper.panel = panel.conf) |
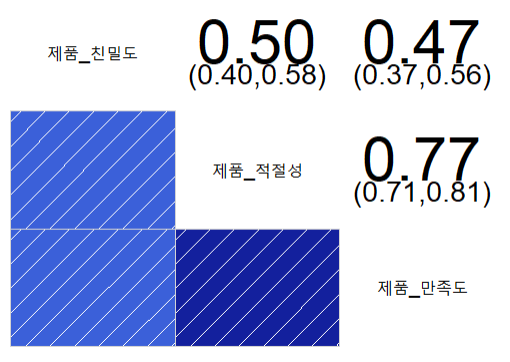
| corrgram(product, lower.panel = panel.conf) |
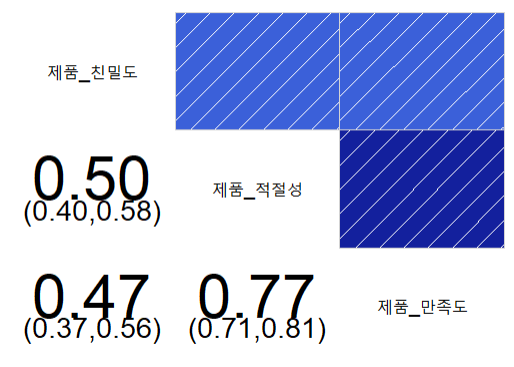
ex) 차트에 밀도곡선, 상관성, 유의확률(별표) 추가
#1 패키지 설치
PerformanceAnalytics 패키지 설치
| install.packages("PerformanceAnalytics") library(PerformanceAnalytics) |
#2 상관성, p값(*), 정규분포(모수 검정 조건) 시각화
| chart.Correlation(product,histogram = ,pch = "+") |

#3 서열척도 대상 상관계수
| cor(product, method = "spearman") # 제품_친밀도 제품_적절성 제품_만족도 # 제품_친밀도 1.0000000 0.5110776 0.5012007 # 제품_적절성 0.5110776 1.0000000 0.7485096 # 제품_만족도 0.5012007 0.7485096 1.0000000 |
서열척도로 구성된 변수에 대해서 상관계수를 구하기 위해서 “method=spearman”속성 적용
- 피어슨(Pearson)상관계수: 대상변수가 등간척도 또는 비율척도일 때
- 스피어만(Spearman) 상관계수: 대상변수가 서열척도일 때
(3) 상관관계 분석 결과 제시
일반적으로 상관관계 분석 결과를 논문이나 보고서에 제시하는 경우, 해당 변수들의 기본적인 기술통계량(평균과 표준편차)와 피어슨 상관계수를 함께 제시
< 상관관계 분석의 유형 >
- 단순 상관관계: X와 Y간의 상관관계
- 다중(Multiple)상관관계: 둘 이상의 변수들이 다른 한 변수와 관계를 갖는 경우
- 편(Partial)상관관계: 두 변수 관계의 정도를 파악하고자 할 때 제 3의 변수가 두 변수 모두에 영향을 미치고 있는 경우 이를 통제한 다음 분석
- 부분(Semi_partial)상관관계: 제3의 변수가 어느 한 변수에만 영향을 미치는 경우 이를 통제한 후 분석
'통계기반 데이터분석' 카테고리의 다른 글
| [ R ] 주성분분석 PCA (0) | 2022.11.25 |
|---|---|
| [ R ]상관계수 (0) | 2022.11.25 |
| [ R ]카이제곱검정 (0) | 2022.11.24 |
| [ R ] 교차분석 (0) | 2022.11.24 |
| [ R ] 집단간 차이분석 - 세 집단 검정 #3 (0) | 2022.11.23 |


